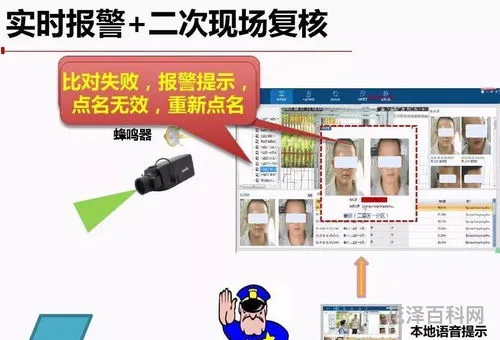
人脸识别数据标注
用*或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部识别的一系列相关技术,通常也叫做人像识别、面部识别。
IMDB-WIKI人脸数据库是有IMDB数据库和Wikipedia数据库组成,其中IMDB人脸数据库包含了460,723张人脸图片,而Wikipedia人脸数据库包含了62,328张人脸数据库,总共523,051张人脸数据库,IMDB-WIKI人脸数据库中的每张图片都被标注了人的年龄和性别,对于年龄识别和性别识别的研究有着重要的意义。
这是由*中文大学汤晓鸥教授实验室公布的大型人脸识别数据集。该数据集包含有200K张人脸图片,人脸属性有40多种,主要用于人脸属性的识别。
这个数据集包含了1521幅分辨率为384x286像素的灰度图像。每一幅图像来自于23个不同的测试人员的正面角度的人脸。为了便于做比较,这个数据集也包含了对人脸图像对应的手工标注的人眼位置文件。图像以"BioID_xxxx.pgm"的格式命名,其中xxxx代表当前图像的索引(从0开始)。类似的,形如"BioID_xxxx.eye"的文件包含了对应图像中眼睛的位置。
LFW数据集是为了研究非限制环境下的人脸识别问题而建立的。这个数据集包含超过13,000张人脸图像,均采集于Internet。
ai数据标注
这是哥伦比亚大学的公众人物脸部数据集,包含有200个人的58k+人脸图像,主要用于非限制场景下的人脸识别。
YouTubeVideoFaces是用来做人脸验证的。在这个数据集下,算法需要判断两段视频里面是不是同一个人。有不少在照片上有效的方法,在视频上未必有效/高效。
FDDB是UMass的数据集,被用来做人脸检测(FaceDetection)。这个数据集比较大,比较有挑战性。而且作者提供了程序用来评估检测结果,所以在这个数据上面比较算法也相对公平。
为促进人脸识别算法的研究和实用化,美国国防部的CounterdrugTechnologyTransferProgram(CTTP)发起了一个人脸识别技术(FaceRecognitionTechnology简称FERET)工程,它包括了一个通用人脸库以及通用测试标准。到1997年,它已经包含了1000多人的10000多张照片,每个人包括了不同表情,光照,姿态和年龄的照片。
CMUPIE人脸库建立于2000年11月,它包括来自68个人的40000张照片,其中包括了每个人的13种姿态条件,43种光照条件和4种表情下的照片,现有的多姿态人脸识别的文献基本上都是在CMUPIE人脸库上测试的。
人脸关键点标注
该数据库是由10位日本女性在实验环境下根据指示做出各种表情,再由照相机拍摄获取的人脸表情图像。整个数据库一共有213张图像,10个人,全部都是女性,每个人做出7种表情,这7种表情分别是:sad,happy,angry,disgust,surprise,fear,neutral.每个人为一组,每一组都含有7种表情,每种表情大概有3,4张样图。
该图为误差图,其中横坐标为每个人的图片编号,纵坐标为每个人的编号,蓝色代表预测正确,*代表预测错误。
分类过程:1,计算已训练集中样本与待测样本之间的距离2,按距离排序3,选取与当前样本距离最小的k个邻居样本4,确定此k个样本中各个类别的频率5,频率最高的类别作为该样本的预测分类








添加新评论